Recent progress in diffusion models has greatly enhanced video generation quality, yet these
models still require fine-tuning to improve specific dimensions like instance preservation,
motion rationality, composition, and physical plausibility. Existing fine-tuning approaches
often rely on human annotations and large-scale computational resources, limiting their
practicality. In this work, we propose GigaVideo-1, an efficient fine-tuning framework that
advances video generation without additional human supervision. Rather than injecting large
volumes of high-quality data from external sources, GigaVideo-1 unlocks the latent potential of
pre-trained video diffusion models through automatic feedback. Specifically, we focus on two key
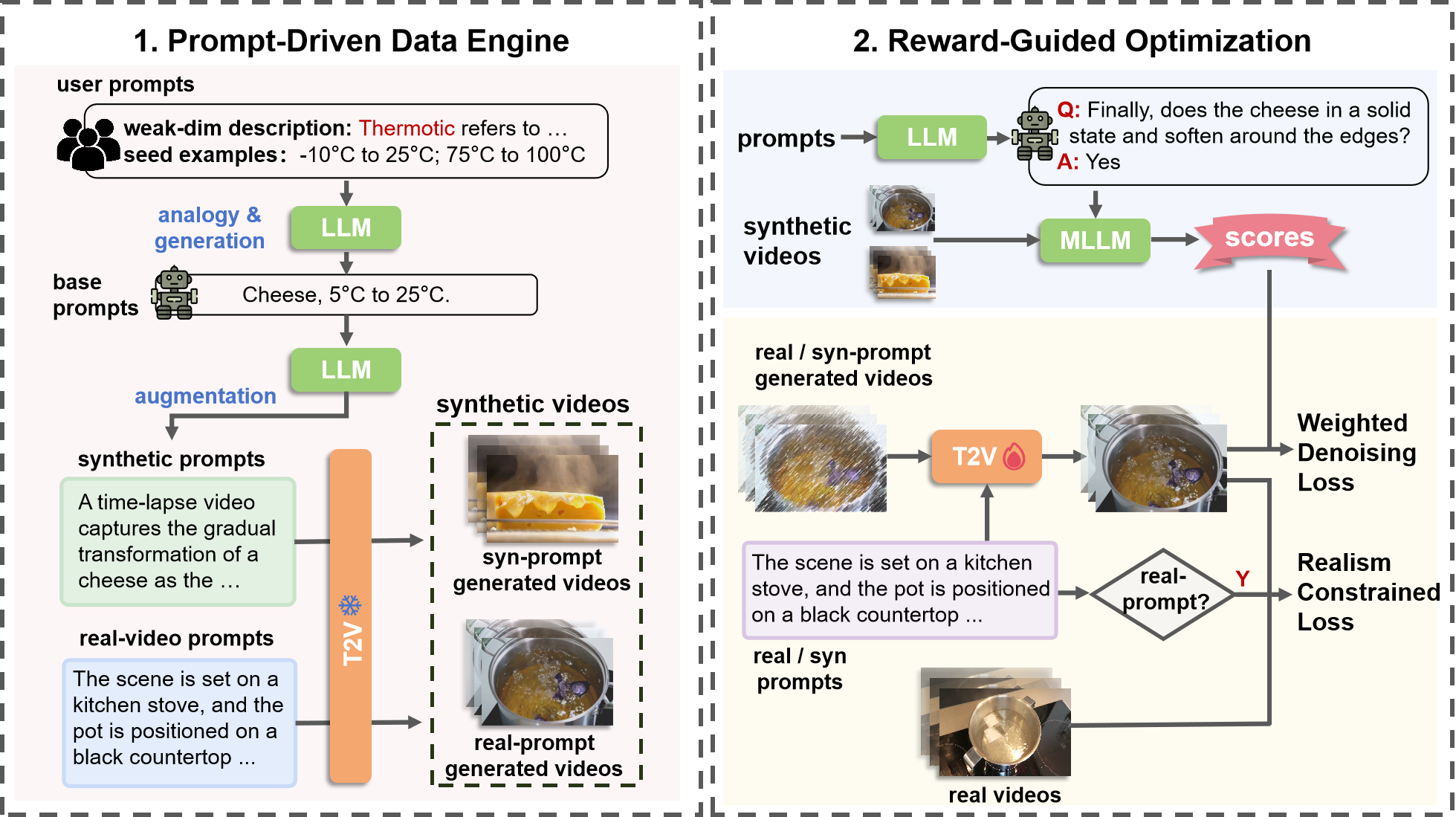
aspects of the fine-tuning process: data and optimization. To improve fine-tuning data, we
design a prompt-driven data engine that constructs diverse, weakness-oriented training samples.
On the optimization side, we introduce a reward-guided training strategy, which adaptively
weights samples using feedback from pre-trained vision-language models with a realism
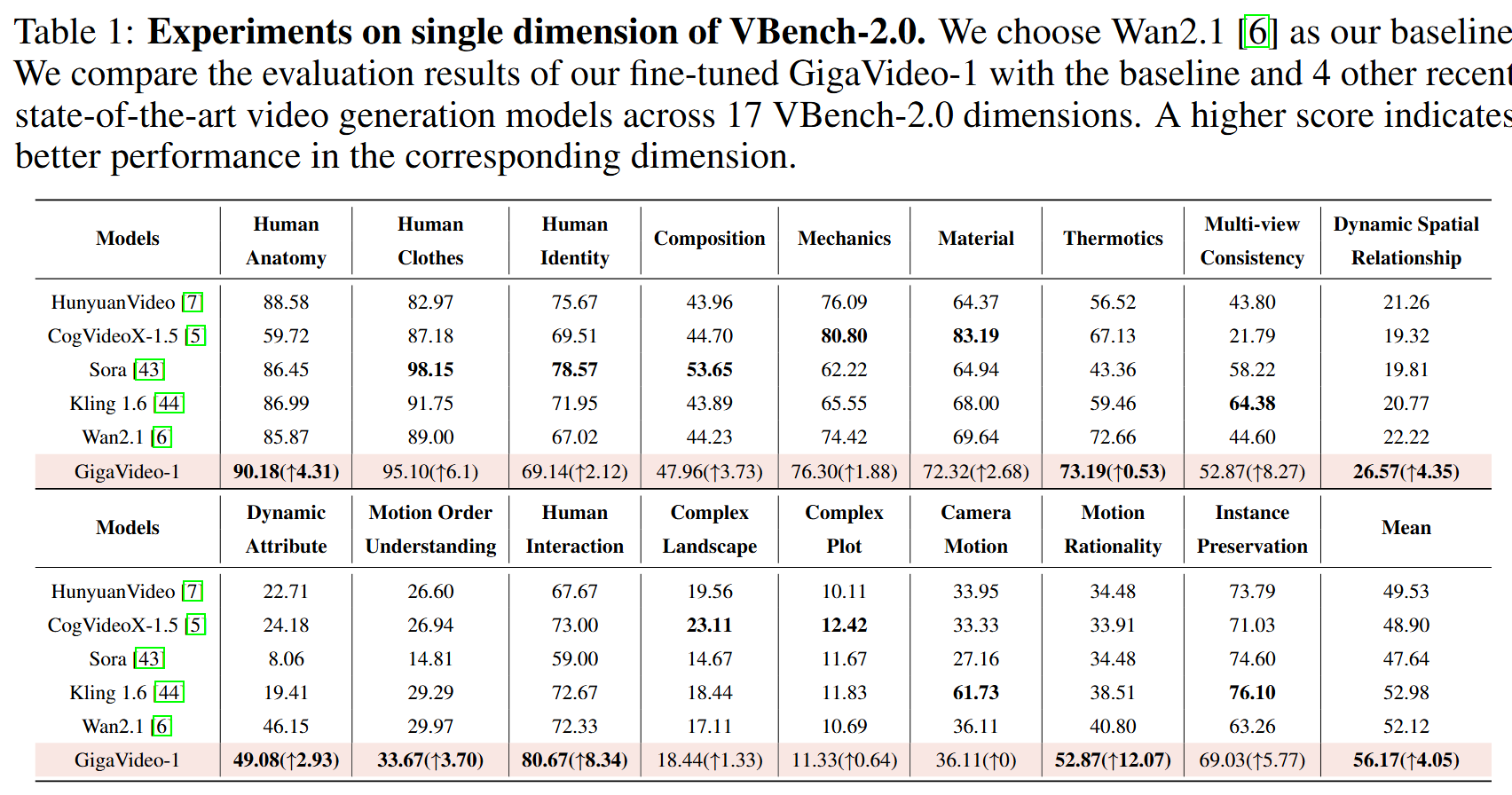
constraint. We evaluate GigaVideo-1 on the VBench-2.0 benchmark using Wan2.1 as the baseline
across 17 evaluation dimensions. Experiments show that GigaVideo-1 consistently improves
performance on almost all the dimensions with an average gain of ~4% using only 4 GPU-hours. Requiring no manual annotations and minimal real data, GigaVideo-1 demonstrates both
effectiveness and efficiency. Code, model, and data will be publicly available.